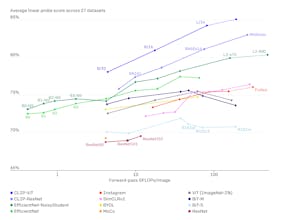
CLIP efficiently learns visual concepts from natural language supervision; it can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero-shot” capabilities of GPT-2 and 3.